1. 인프런 생활코딩 - linux 강의 섹션 9 수강 후 강의 리뷰 & 어려웠던 점, 흥미로웠던 점 공유
[검은 배경의 사용자 egoing / ubuntu 서버 자료 일부 해당 강의 발췌했습니다.]
2. 달고나 문서 (~ chap 05) 내용 요약
[ linux ]
웹서버: 웹브라우저에게 response 해주는 프로그램으로 서버컴퓨터에 웹서버가 설치되어있어야 웹 서비스가 가능하다.
client로 사용하기 위해서는 web browser가 있어야 한다.
웹 브라우저에 해당하는 제품: firefox, ie, chrome 등
웹 서버에 속하는 제품: Apache, nginx, IIS 등
Apache 웹서버 설치 & 실행
설치: sudo apt-get install apache2
실행: sudo service apache2 start
종료: sudo service apache2 stop
재시동: sudo service apache2 restart

F4키 누르면 여러 개의 아파치 웹서버가 자동으로 실행이 되는걸 볼 수 있다.
접속 – 웹서버 구동 확인
Elinks: 셸에서 웹브라우징을 할 수 있게 도와주는 프로그램



127.0.0.1은 자신의 아이피를 가리킨다.

설정
Unix 계열에서의 설정에 대한 것은 /etc에 저장되어 있다.
etc/apache2/: 설정이 저장되어 있는 경로
apache2.conf: 설정 파일

Cd /etc 입력하면
여러가지 프로그램들의 동작 방법인 설정이 저장되어 있는 것을 확인할 수 있다.

그 중 apache2.conf를 확인하면 Include Optional sites-enabled/\*.conf가 있는데 sites-enabled라는 디렉토리 안의 모든 .conf 파일을 읽고 사용한다는 것이다.

/var/www/html을 사용하는 이유는 /etc/apache2/sites-enabled/000-default.conf 에 설정이 /var/www/html로 되어있기 때문이고

DocymentRoot가 /var/www/html 이기 때문이다.
어떤 서버를 설치하건 /etc 밑에 설정 파일이 있고 그 곳의 설정 파일을 바꾸면 동작하는 방식이 달라진다.
로그

/etc/apache2/sites-enable/000-default.conf → ErrorLog ${APACHE LOG_DIR}/error.log CustomLog ${APACHE LOG_DIR}/access.log combined
${APACHE LOG_DIR}: /var/log/apache2/
누군가가 웹서버에 접속할 때마다 그 파일의 끝에 접속한 사람의 정보가 추가 되는데 실시간으로 확인하고 싶을 때는 tail 명령어를 써주면 된다.
이 명령은 실시간으로 끝에 있는 정보만 출력하는 아주 편리한 옵션이다.
원격제어
SSH(원격제어)
SSH Client -------------------------------> SSH Server (제어하고자 하는 대상)
자신이 원격지에 있는 인터넷 너머에 있는 서버 컴퓨터를 원격 제어를 해야 되는데 그 경우에 SSH라는 걸 쓰고 셸을 통해 제어를 해야 될 컴퓨터의 경우 SSH 사용한다.
대부분의 unix 계열 시스템에는 ssh가 기본적으로 설치되어 있다.
설치: sudo apt-get install openssh-server openssh-client
확인: sudo ps aux | grep ssh
접속: ssh [username]@[ip address]
접속종료: exit
다른 컴퓨터임에도 불구하고 원격으로 다른 컴퓨터에 접속할 수 있다. 이 컴퓨터로 명령을 내리면 ssh로 접속한 컴퓨터를 대상으로 실행되게 된다.
설치가 끝나면
sudo service ssh start 입력 -> 프로세스 출력

이렇게 SSH가 나오면 잘 실행되고 있고 설치된 상태라고 말할 수 있다.
포트
client는 port를 통해서 server에 접속하고
실습을 하면
www.naver.com/80 ->접속가능
www.naver.com/8888 -> 접속불가 된다. 이 결과로
80이 port 라는 걸 알 수 있었다.

마찬가지로 2222는 거절되고 22는 접속이 된다는 건 SSH라고 하는 방식은 22번 포트를 쓴다는 것을 알 수 있다.
web: 80 port
ssh: 22 port
포트번호 변경: /etc/ssh/sshd_config(ssh server 설정파일)에서 포트번호를 수정하고 재시작하면 포트번호가 변경된다.
포트 포워딩
라우터의 특정 포트로 접근하면 네트워크에 연결되어 있는 특정 컴퓨터의 특정 포트로 전달하여 접속이 가능하게 하고 라우터에서 환경설정을 해주어야 한다.

Ip route로 확인하면

192.168.0.65 라는 것을 알아낼 수 있다.

외부 포트: 사용자가 사용할 포트 번호
내부 포트: 서버를 설치할 컴퓨터의 포트 번호

linuxlove라는 규칙에 의해서 9000번 포트로 누군가 들어왔을 때 192.168.0.65에 해당하는 컴퓨터의 80번 포트로 신호를 보낸다라고 규칙을 정해 놓는 것이다.
[ 달고나 문서 ]
5. buffer overflow의 이해
buffer overflow의 작동 방식
buffer overflow는 미리 준비된 버퍼에 버퍼의 크기보다 큰 데이터를 쓸 때 발생하게 된다.

예를 들어 <그림 14>에서 보듯이 스택의 모습은 40바이트의 스택이 준비되어 있으나 40바이트보다 큰 데이터를 쓴다면 아무런 지장이 없을 것이다. 만약 40바이트 이상의 데이터를 쓴다면 이전 함수의 base pointer를 수정하게 될 것이다.
여기서 시스템에게 첫 명령어를 간접적으로 내릴 수 있는 부분은 return address가 있는 위치이다. return adress는 현재 함수의 base pointer 바로 위에 있으므로 그 위치는 변하지 않는다. 따라서 buffer overflow 공격은 공격자가 메모리상의 임의의 위치에다 원하는 코드를 저장시켜 놓고 return address가 저장되어 있는 지점에 그 코드의 주소를 집어 넣음으로 해서 EIP에 공격자의 코드가 있는 곳의 주소가 들어가게 해 공격을 막는 방법이다.
strcpy(buffer2, receive_from_client);
이 코드는 client로부터 수신한 데이터를 buffer2와 buffer1에 복사한다.

클라이언트인 공격자가 전송하는 데이터는 receive_from_client에 저장되어 버퍼에 복사될 것이다. 그 데이터가 <그림15>와 같이 구성하여 전송한다고 가정한자. 그리고 strcpy가 호출되어 receive_from_client가 buffer2에 복사가 될 것을 생각하면 <그림14>와 <그림15>를 함께 보았을 때 다음과 같이 매칭될 것이다.


receive_from_client의 데이터를 버퍼에 복사한 후에 모습이다.
Byte order
데이터가 저장되는 순서가 바뀐 이유는 바이트 정렬 방식이다. big endian 방식과 little endian 방식이 있다. big endian 방식은 바이트 순서가 낮은 메모리 주소에서 높은 메모리 주소로 되고 little endian 방식은 높은 메모리 주소에서 낮은 메모리 주소로 되어있다.
즉 낮은 수의 변화는 낮은 메모리 영역에 영향을 받고 높은 수의 변화는 높은 메모리 영역에 자리를 잡게 하겠다고 하는 것이 little endian 방식의 논리이다. 높은 메모리에 있는 바이트가 변하면 수의 크기는 크게 변한다는 말이다. 하지만 한 바이트 내에서 bit의 순서는 big endian 방식으로 정렬된다.
이러한 byte order 문제 때문에 공격 코드의 바이트를 정렬하 때에는 이러한 문제점을 고려해야 한다. little endian 시스템에 return address 값을 넣을 때는 바이트 순서를 뒤집어서 넣어주어야 한다.
<그림17>은 함수 실행이 끝나고 ret instruction을 만나면 return address가 있는 위치의 값을 EIP에 넣을 것이고 이제 EIP가 가리키는 곳의 명령을 수행하려 할것이다. 이 때 이 주소에 명령어가 들어 있지 않다면 프로그램은 오류를 발생시키게 된다. 또한 공격자는 자신이 만든 공격 코드를 실행하기를 원하므로 EIP에 returun address 위에 있는 쉘 코드의 시작 주소를 얻고 싶어한다. 어떻게 하면 이 주소를 알아낼 수 있을까?
일단 쉘 코드가 들어있는 지점의 정확한 주소를 찾았다고 생각하자.

다음과 같다.
<그림 18> 에서 보여주는 공격코드는 execve("/bin/sh", ...) 이다. 이것이 바로 bufer overflow를 이용한 공격방법이다.
만날 수 있는 문제점 한가지
<그림 18>에서의 공격 코드는 총 24바이트 공간 안에 들어가 있다. 하지만 공격 코드가 24바이트로 만들어 지지 못할 경우가 있을 수 있다. 따라서 간접적으로 그 곳으로 명령 수행 지점을 변경해 주는 방법을 사용한다.
<그림 19>는 ESP 값을 이용하여 명령 수행 지점을 지정해 주는 방법을 보여주고 있다.

<그림 19>에서는 쉘 코드가 return address 아래에 있다. 따라서 ESP는 return address가 있던 자리 위를 가리키게 된다.
따라서 return address 이후의 버퍼 공간이 부족할 경우 이전의 버퍼 공간을 활용하는 방법을 설명하였다,
쉘 코드 만들기
쉘은 사용자의 키보드 입력을 받아서 실행파일을 실행시키거나 커널에 어떠한 명령을 내릴 수 있는 대화통로이다. 쉘 코드는 바이너리 형태의 기계어 코드이다. 쉘 코드를 만들어야하는 이유는 실행 가능한 형태의 명령어를 만들어야 하기 때문이다.
쉘 실행 프로그램
우리가 쉘 상에서 쉘을 실행시키려면 '/bin/sh' 라는 명령을 내리면 된다.
아래의 코드를 보자.

쉘을 실행시키기 위해서 execve()라는 함수를 사용했다. 이 함수는 바이너리 형태의 실행 파일이나 스크립트 파일을 실행시키는 함수이다. 이제 이 프로그램이 컴파일되어 생성될 바이너리 코드를 얻어야 한다.
Dynamic Link Library & Static Link Library
Dynamic Link Library는 우리말로는 동적 링크 라이브러리라고 해석된다. 같은 기능을 하는 기계어 코드가 서로 다른 실행파일에 모두 포함되어있는 낭비를 막기 위해 직접 구현 필요 없이 호출만 하게 해주는 것이다.
하지만 운여에제의 버전과 libc의 버전에 따라 호출 형태나 링크 형태가 달라질 수 있기 때문에 이제 영향을 받지 않기 위해서 기계어 코드를 실행파일이 직접 가지고 있게 할 수 있는데 그 방법이 Static Link Library이다.

그러면 이제 sh.c 프로그램에서 호출하는 execve() 함수의 내부까지 들여다 보기 위해서 Static Link Library 형태로 컴파일 한 후 기계어 코드를 살펴보자.


sh.c 를 static link library로 컴파일 하여 sh라는 실행파일을 만들었다.

굵게 표시한 부분만 보자. 이러한 작업을 하는데 정리해서 보면

다음과 같다.
이것은 ebp 레지스터가 가리키는 곳에 +8 바이트 지점의 값을 ebx 레지스터에 넣고, +12바이트 지점의 값을 ecx 레지스터에 넣고, +16바이트 지점의 값을 edx 레지스터에 넣어라는 뜻이다.
그런 다음

eax 레지스터에 11을 넣고 int $0x80을 하였다. 이 과정이 system call 과정이다.
int $0x80을 호출하기 이전에 eax 레지스터에 시스템 콜 벡터를 지정해 줘야 하는데 execve()에 해당하는 값이 11(0xb)인 것이다. 정리해서 다시 말하면 11번 시스템 콜을 호출하기 위해 각 범용 레지스터에 값들을 채우고 시스템 콜을 위한 인터럽트를 발생시킨 것이다.
다음은 exeve()를 호출하기 이전에 main()에서는 어떤 처리를 했었는지 알아보자.

main()함수에서는 execve()를 호출하기 위해서 세 번의 push를 한다. 이는 execve()의 인자로 넘겨주는 값이라는 것을 짐작할 수 있을것이다.
두꺼운 글씨 부분의 코드를 살펴보자.
제일 처음 '/bin/sh'라는 문자열이 들어있는곳의 주소(0x8089728)를 ebp 레지스터가 가리키는 곳의 -8 바이트 지점(0xfffffff8)에 넣는다. 그리고 ebp - 4byte 지점(0xffffffc)에는 0을 넣는다. 이것은 sh.c에서
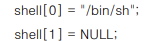
다음과 같은 역할을 한다.
다음으로 NULL을 PUSH하고 ebp+8의 주소를 eax 레지스터에 넣은 다음에 eax 레지스터를 PUSH한다. ebp+8의 값을 PUSH하고 execve()를 호출한다.

수행을 마치면 다음과 같다.
따라서 정리하면 쉘을 띄우기 위한 과정은 다음과 같다.
1. 스택에 execve()를 실행하기 위한 인자들을 제대로 배치하고
2. NULL과 인자값의 포인터를 스텍에 넣어 두고
3. 범용 레지스터에 이 값들의 위치를 지정해 준 다음에
4. interrupt 0x80을 호출하여 system call 12를 호출하게 하면 된다.

다음 코드는 'bin/sh'가 어느 지점에 저장되어 있다는 것을 기대하기도 어렵고 또한 있다고 하더라도 저장되어 있는 메모리 공간의 주소를 찾기도 어렵기 때문에 직접 넣어주어야 할 때 쓰는 코드이다.
이제 이 코드가 제대로 동작하는지 컴파일 해 보도록 하자. 이 코드는 C 프로그램 내에 인라인 어셈블로 코딩 할 것이고 main()함수 안에 들어갈 것이기 때문에 함수 프롤로그가 필요 없다. 컴파일러가 알아서 함수 프롤로그를 만들어줄 것이기 때문이다. '/bin/sh'를 16진수 형태로 바꾸고 main()함수 안에 넣어서 작성한 sh01.c의 코드는 아래와 같다.
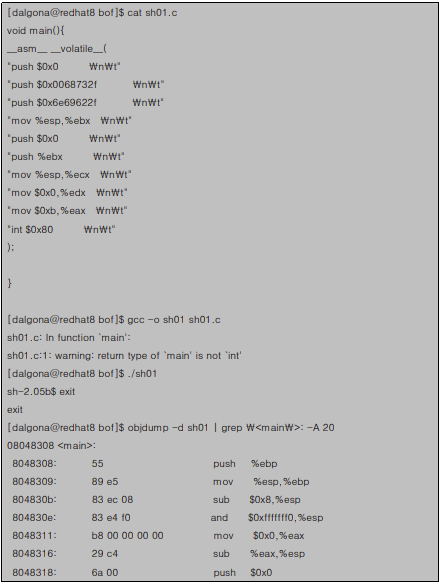

지금까지 bufferoverflow의 작동방식에 대해 살펴보았다.
NULL의 제거(44-53p)
Buffer overflow 공격 수행을 위해 shell을 통해 동적 링크 라이브러리 & 정적 링크 라이브러리를 구현하는 방법을 보았다.
여기서 문제점이 발견되었는데, 이렇게 얻은 기계어 쉘 코드를 문자열 형태로 전달할때, push 0x00과 같은 char a[] = "\x6a\x00"형태의 코드들이 0x00 이후의 값이 어떤 값이든 무시하게 되는 것이다. (char형 배열은 0의 값을 만나면 그것을 문자열의 끝으로 인식한다) mov $0xb, %eax 등 0x00과 같은 형태의 기계어 코드는 상당히 많다.
[이와 같은 문제(\x00)를 해결하기 위해 존재하는 코드들]


적용 후 모습이다.
xor %eax,%eax (8048304) 이후부터 int $0x80 (804831b) 사이 기계어 코드에는 00이 존재하지 않는다. NULL로 인식될 염려가 없어진 것이다.
char형 배열에 16진수 형태의 바이너리 데이터를 전달할 것이기 때문에 해당 데이터들을 문자열화 시켜 보았다.

만든 기계어 코드 추출값을 재가공한 결과. (결과값은 모두 한 줄에 써도 무방)
해당 쉘 코드를 실행시키기 위해 프로그램을 작성된 프로그램이다.

쉘이 잘 뜨는 모습을 볼 수 있다.
원리를 이해해보기 위해 disassemble해보면

함수 프롤로그 수행 후 실행되는 코드들
- 먼저 ebp-4byte 지점의 address를 eax 레지스터에 넣는다. 그 다음 그 address에 8을 더한다.
- [sh03.c에서 ret = (int*)&ret + 2; 하는 과정] -> 해당 과정에서는 ret라는 포인터 변수의 address를 찾아 8바이트 상위의 주소로 만든다.
- ebp+4 지점에 return address의 값을 넣고, return address가 들어 있는 주소 값은 ebp-4byte 지점에 넣는다. 거꾸로도 수행한다.
- eax 레지스터 값이 가리키는 지점에 $0x804936c(char sc[] 데이터가 있는 지점)를 넣어준다.
- main()함수가 종료되고, EIP는 return address가 가리키는 지점에 있는 명령을 가리키게 된다.
해당 과정을 거치면 우리가 만든 쉘 코드가 들어있는 위치를 가리키게 되므로, 시스템이 쉘 코드를 수행하게 된다.
[다른 방법]
쉘 코드를 저장할 변수를 int형으로 만들어 준다.
주의) 코드를 little endian 순서로 정렬하고, int 형이기 때문에 4byte단위로 만들어야 한다.

int형으로 만들어진 쉘 코드. 바이너리 데이터를 메모리에 넣고 실행시키는 방법
int형 배열을 사용하거나 char형 배열을 사용해도 상관 없으나, 대부분의 buffer overflow 공격 방법이 문자열형 데이터 처리의 실수를 이용하는 것이므로 char형이 int형보다 더 편하다. (int형은 코드 재졍렬 등의 귀찮음이 따른다.)
[setreuid(0,0)와 exit(0)가 추가된 쉘 코드]
buffer overflow 공격 성공시 얻게되는 쉘 외에도 다른 많은 권한을 얻고 싶을때, root 권한을 얻을 수 있는 방법을 모색하게 된다.
setuid비트가 set되어 있는 프로그램을 오버플로우시켜 쉘 코드를 실행시키고 루트의 쉘을 얻어낼 방법이 필요한데,
위의 sh03.c와 sh04.c는 root 권한을 얻어주지 못하기 때문에 우선 sh03dp setuid 비트를 붙여 실행시켜보면
- root 소유 프로그램의 권한을 그대로 상속받지 못했고
- 쉘 코드에 소유자의 권한을 얻어내는 기능이 필요하기 때문에 아무런 역할을 하지 못한다.
쉘 코드를 다시 수정해야 한다.

setreuid()함수를 통한 프로그램 소유자 권한 탈취
쉘 코드에 setreuid()가 실행하는 기계어 코드를 추가한 모습이다.
해당 기계어 코드를 찾는 방법은 앞서 설명한 execve()에서 기계어 코드를 찾는 방법과 동일하게 수행할 수 있다.
static으로 컴파일하여 setreuid()함수를 찾아 인터럽트를 호출하는 부분을 찾으면 된다.

찾아진 기계어 코드와 어셈블리 코드를 이전의 쉘 코드 앞부분에 단순히 붙여주기만 한 모습
+) 더 완벽한 쉘 코드를 만들기 위해서 exit(0) 추가
공격자가 overflow 공격을 수행하고 난 뒤 프로그램의 정상적 종료를 위한 기능이 필요하다.

exit 코드

exit 기능을 추가해 정상적 종료가 수행되는 소유자 권한 탈취코드
소유자 권한으로 쉘을 실행시키는 쉘 코드가 잘 만들어 졌다.
'3. Pwnable (포너블)' 카테고리의 다른 글
| [2024.09.21]PWN PWN 해 1주차 활동 (0) | 2024.11.15 |
|---|---|
| [2023.11.11] 포너블 5주차 팀활동 (0) | 2023.11.14 |
| [2023.10.14] 포너블 3주차 팀활동 (0) | 2023.10.19 |
| [2023.10.07] 포너블 2주차 팀활동 (0) | 2023.10.13 |
| [2023.09.23] 포너블 1주차 팀활동 (1) | 2023.10.05 |
